Concepts
Five Node Classes
Every node in the DAG is classified into one of five semantic roles:
Class |
Role |
Examples |
|---|---|---|
Source |
Data acquisition scripts |
|
Input |
Raw data and configuration |
|
Processing |
Transform and analysis scripts |
|
Output |
Intermediate and final data products |
|
Claim |
Manuscript assertions tied to evidence |
|
This classification turns the DAG into a navigable map of the research project. The key operation is backpropagation from claims to sources: starting from a manuscript assertion (claim), Clew traces backward through outputs, processing scripts, and inputs to the original raw data — verifying every hash along the way.
Three Verification Modes
Mode |
Scope |
API |
Description |
|---|---|---|---|
Project |
Entire pipeline |
|
Verifies every session in the database in topological order. “Is the whole project intact?” |
Files |
Specific outputs |
|
Traces backward from target files through their dependency chain. “Can I trust this specific file?” |
Claims |
Manuscript assertions |
|
Verifies claims linked to source sessions. “Is this figure still backed by the data?” |
DAG as Research Logic
Beyond verification, the DAG itself is valuable: it is the simplest formal representation of a project’s research logic. Each node is a concrete artifact (script, data file, or claim) and each edge is a recorded dependency. This skeleton structure lets you:
Understand a project at a glance — which scripts produce which outputs
Navigate from any claim back to the raw data that supports it
Communicate project structure to collaborators and reviewers
Enable AI agents to reason about the research pipeline programmatically
The Mermaid diagram (clew.mermaid()) renders this logic as a visual flowchart,
making the implicit structure of any research project explicit and inspectable.
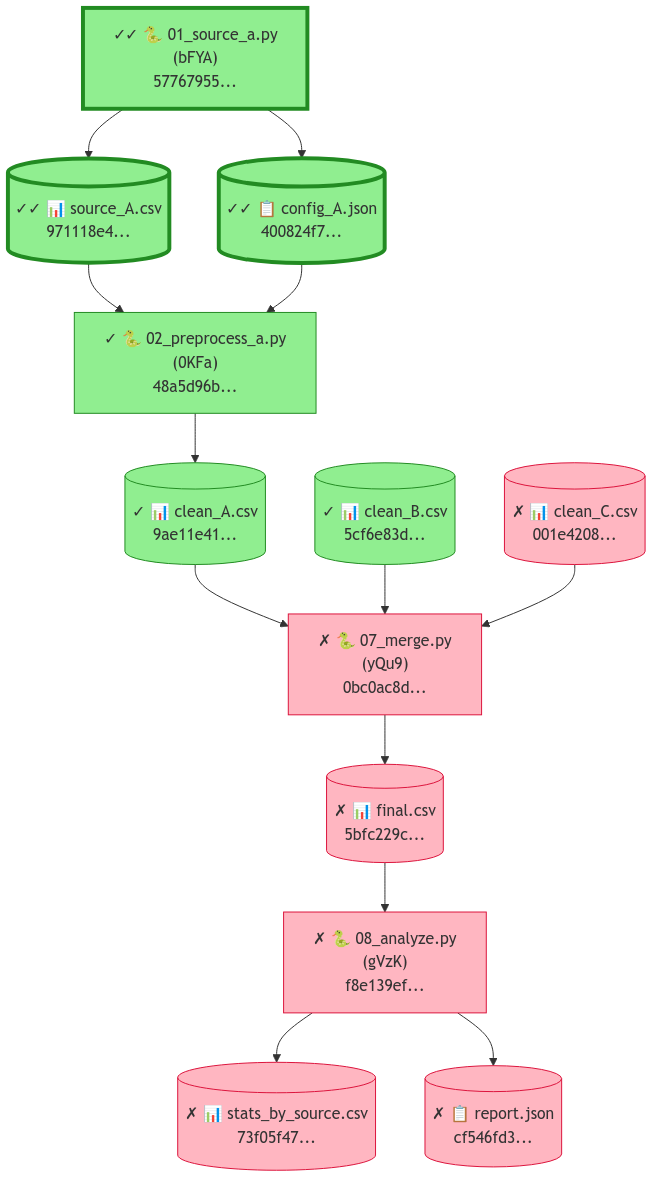
Figure 2. The DAG is both a verification tool and a structural map of research logic — from raw data through processing to manuscript claims.
How It Works
Recording: During a session, Clew computes SHA-256 hashes of all input and output files, storing them alongside session metadata in a local SQLite database.
Verification: At any point, you can verify a session by recomputing hashes and comparing them to the recorded values. If any file has changed, the verification fails.
DAG Construction: Sessions are linked by shared files — when one session’s output is another session’s input, Clew infers a dependency edge. This builds a complete DAG of the research project.
Provenance Tracing: Given any file, Clew can trace its complete lineage — which sessions produced it, which inputs were consumed, and whether the chain is intact.
Claim Verification: Manuscript assertions (e.g., “Figure 1 shows p < 0.05”) are linked to the sessions that produced the evidence. Verification ensures the claim is still supported by the data.
Verification Caching Guarantee
Clew caches for speed but never at the cost of correctness: every cache is
keyed by content hash (SHA-256 of the live file bytes). There is no
mtime-based logic anywhere in the package (verified at v0.6.0: a grep for
mtime across src/*.py returns zero matches). A cache can therefore
speed up verification but can never return “verified” for content that has
changed.
Per-pass hash cache (
src/scitex_clew/_chain/_hash_cache.py): each top-level verification pass shares one{resolved path: hash}dict so a file referenced by many sessions is hashed once per pass. The dict is created fresh at every entry point and never persisted — a file changed between two passes is always re-hashed.Freshness-skip (
rerun_dag(skip_unchanged=True),src/scitex_clew/_chain/_freshness.py): opt-in. Re-hashes the script and every recorded input against the recorded values before skipping a sandbox re-execution; any mismatch falls through to a real re-run. Skipped sessions are markedlevel=CACHE(notRERUN). Outputs are not re-hashed by this check — pair with an L1verify_chain()pass to catch output tampering. Assumes deterministic scripts.No persistent verdict cache (as of v0.6.0): stored verification verdicts (
verification_results) are an append-only history; they are never read back to skip or override live hashing.
See the scitex-clew skill (03_python-api.md, “Verification caching —
correctness guarantee”) for the audited per-mechanism statement, including
the explicit frozen hash-trust opt-out.
Architecture
┌─────────────────────────────────────────────────┐
│ scitex-clew │
├─────────────────────────────────────────────────┤
│ Python API (19 functions) │
│ status, run, chain, dag, rerun, mermaid, ... │
├─────────────────────────────────────────────────┤
│ CLI (Click) │ MCP (FastMCP) │
│ clew status │ clew mcp start │
│ clew verify ... │ 9 tools │
├─────────────────────────────────────────────────┤
│ Core Engine │
│ _hash.py _chain/ _claim/ _attest/ │
│ _tracker.py _rerun.py _estimate.py │
├─────────────────────────────────────────────────┤
│ Storage: SQLite (db.sqlite) │
│ runs, file_hashes, session_parents, claims │
└─────────────────────────────────────────────────┘
Zero dependencies — pure stdlib + sqlite3. Optional extras: click (CLI),
fastmcp (MCP server), sphinx (docs).